GRU, LSTM, and RNN application architectures
Gated RNNs
GRU
Gates are used in GRU and LSTM, these are not digital gates here. They generate gate signals ranging from 0 to 1. Usually is produced by sigmoid function whose output ranges from 0 to 1. It is used to mix two signals a and b as convex combination: or scale a signal (considering b to be 0) .
In order to introduce GRU, we first redraw the Jordan RNN where like below:
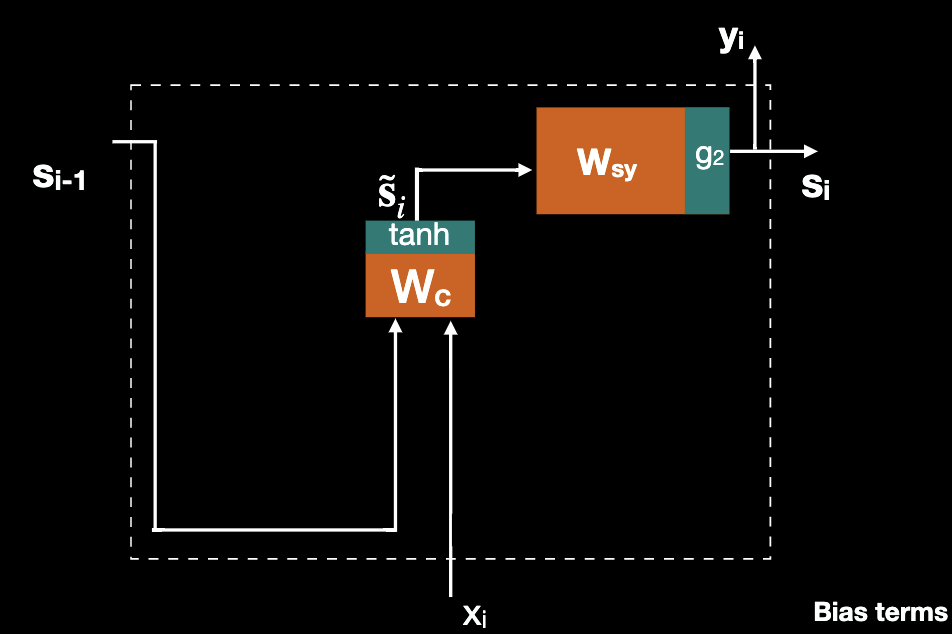
If we add an update gate in parallel to the hidden state, then we have a simple GRU where Where

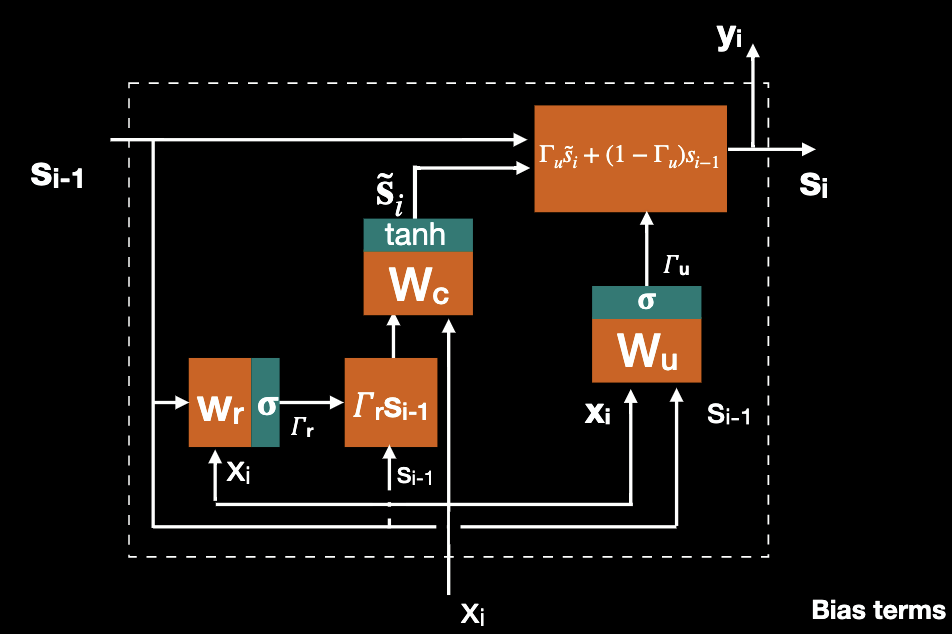
Further adding a reset gate and we formulate the full GRU, where
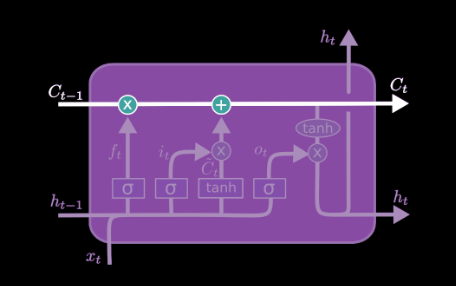
LSTM networks
LSTM stands for long short term memory, and the network has feedback for both state and output. LSTM differs from GRU where there are three gates for LSTM and two for GRU; More subtly, LSTM has 2 “state channels”, 4 layers with four weight matrices: , and 3 gates.
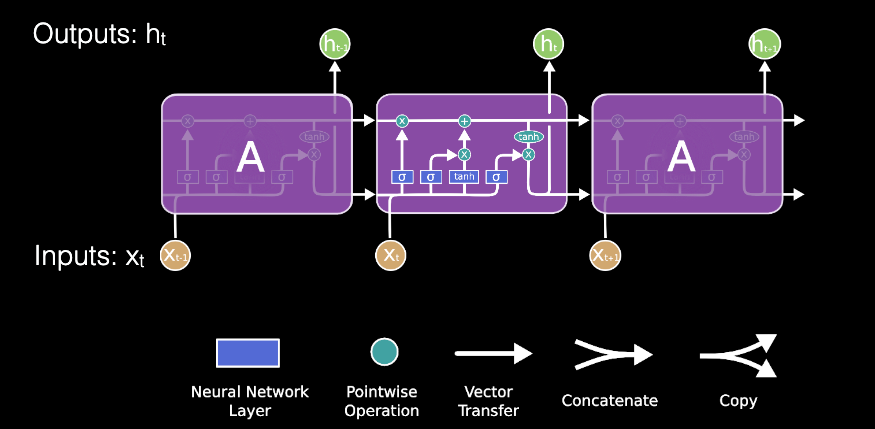
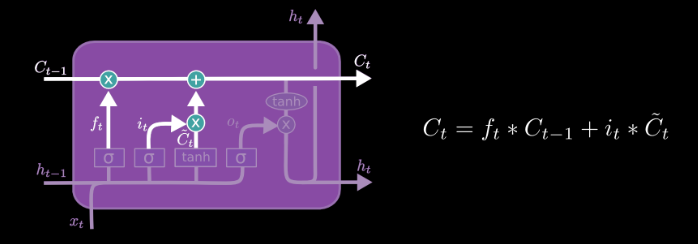
Now let’s look at the different components that make up an LSTM. The two state channels which the output is also fed back to the LSTM unit, which represents additional state information. The cell state is carried forward from one time instance to the next, is modified along the way. Note that state isa vector not a scalar.
An LSTM “gate” makes an element wise decision on what to allow through. It is a fully connected layer followed by a sigmoid with outputs between 0 and 1. It’s like one of the gates in a GRU.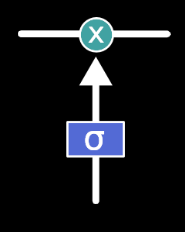
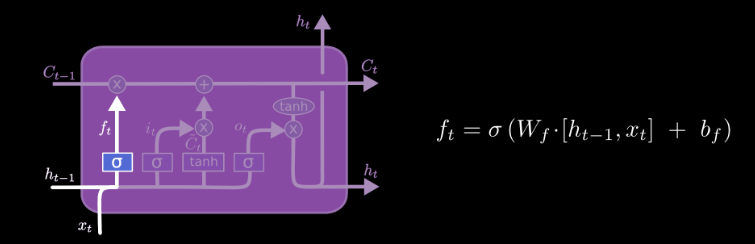
The forget fate decides what elements of the previous cell sate should be forgotten. When an element of is zero, the output of date is zero (forgotten).
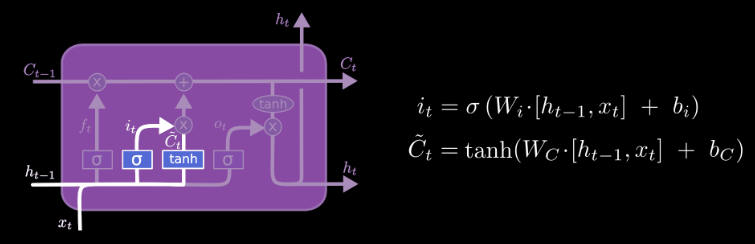
The input gate determines what new information from should be added to create the new cell state, where is the output of full connected layer gives proposed next state change. This new information is linearly transformed and then squashed by the tanh function which forces the output to lie between -1 and 1.
Outputs from the forget gate and the input gate combine to update the current cell state. Note that GRU took convex combination of C and .
The output gate decides what information from the cell state should be output by the LSTM.
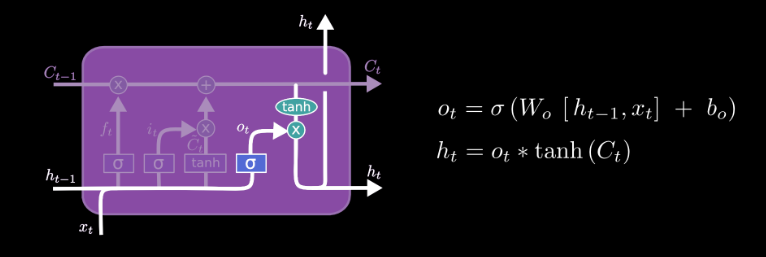
In general, LSTM has 3 gates, more parameters and have been more proven, while GRU has 2 gates, fewer parameters and is better trained on small datasets. Both are implemented in major frameworks and easy to use.

Bidirectional RNN, Multilayer RNN
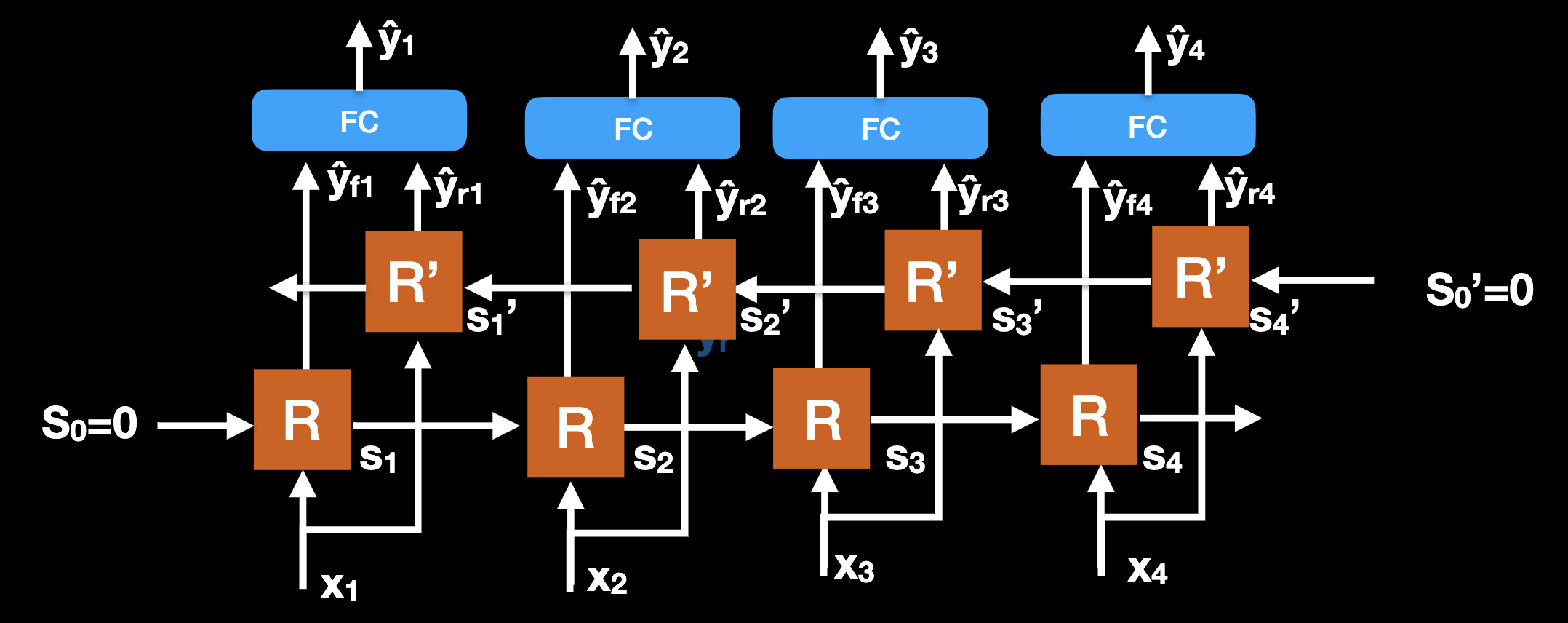
Bidirectional RNN are formed by two independent RNNs (can be any type), in which the forward direction is as usual, the reverse direction starts at end of the sequence and goes backward to start. Once forward and reverse RNNs are complete, outputs for each time step are concatenated, and may be passed through fully connected layer.
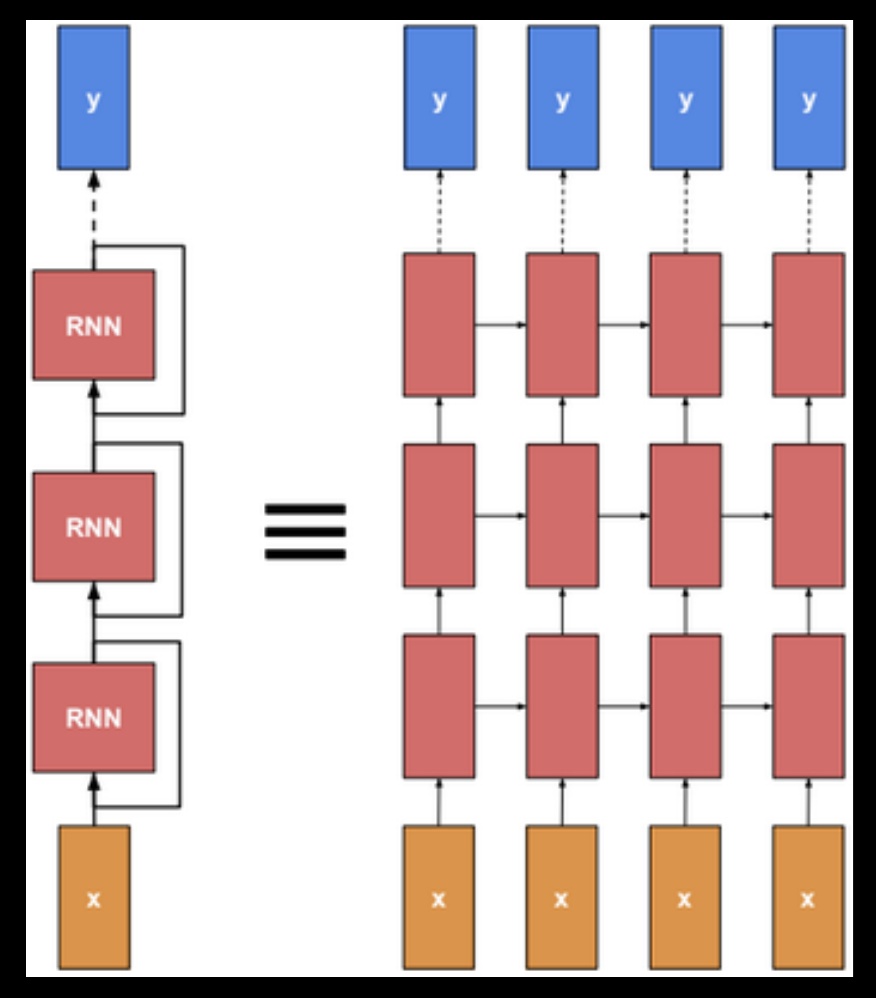
Multilayer RNN can be any RNN type like LSTM or GRU, it can be directional, it can have any number of layers (usually 2 or 3 layers). Sometimes it is called “Deep RNN”, its backdrop depth is really governed by unrolled sequence length, although number of parameters by layers.
RNN Application Architectures
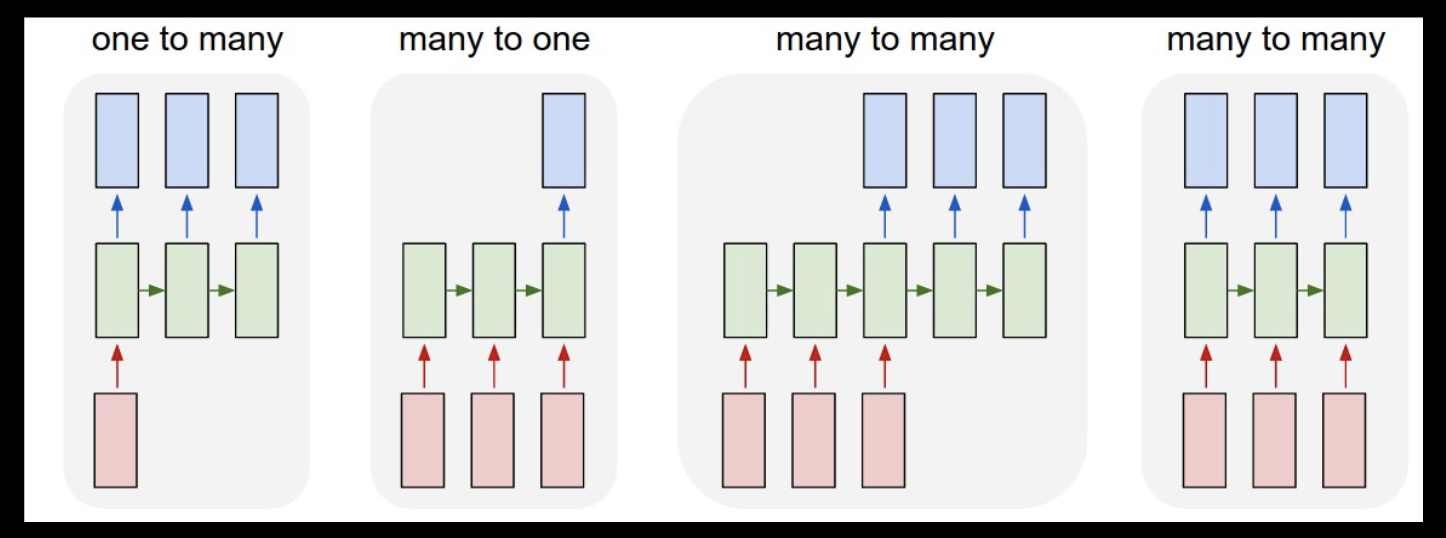
-
One to Many
The one to many architecture applies to sequence generation like audio or speech generation, or image caption generation. Its loss function is defined over all outputs.
-
Many to One
The Many to one architecture applies to sequence classification like sentiment analysis, video classification or stock market “Buy/Sell” decision. Its loss function is defined over single output and is usually cross entropy.
-
Many to Many (same length)
It is usually used for classifying elements of a sequence such as Named Entity classification, video segmentation/activity labeling, statistical language model (char RNN), and some approaches to speech recognition. Its loss function is defined over all outputs and is usually sum of losses for each output.
-
Many to Many (different length)
This architecture is often called Encoder-Decoder architecture with two RNNs. The input sequence is encoded into a vector, the output sequence is generated from such vector. It is widely used in language translation, video captioning, and Question-Answering.
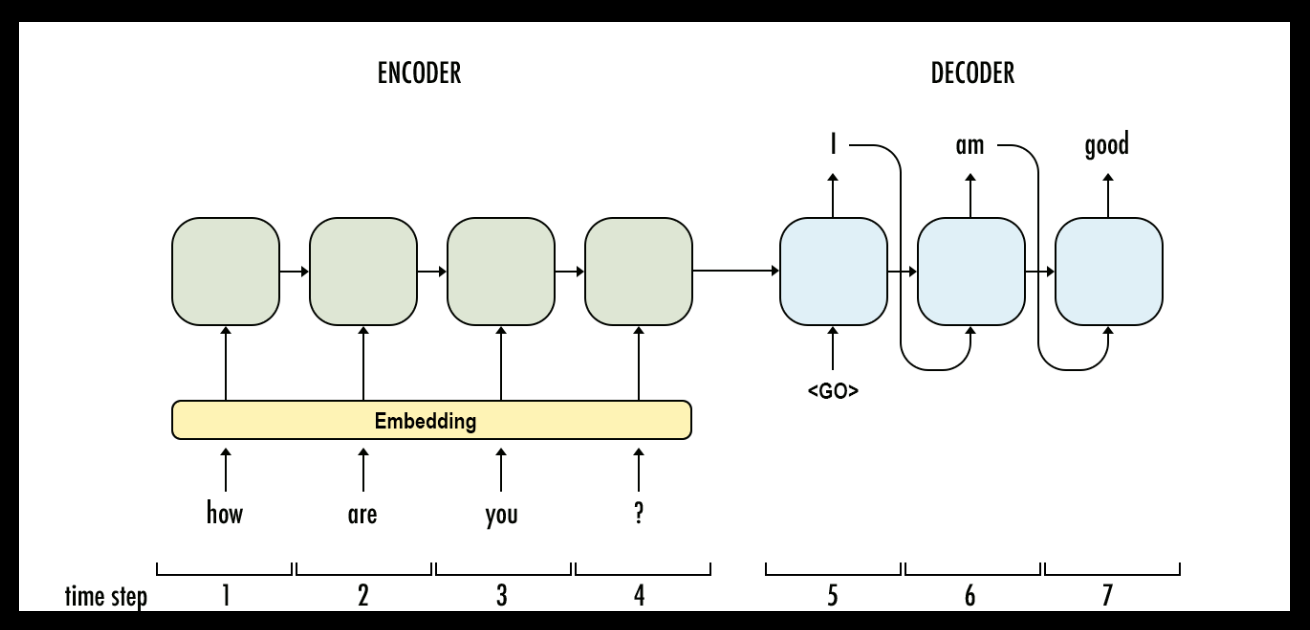
Inference with beam search
In sequence generation or sequence-to-sequence problems, we want to find where x is the input (an image, a sequence etc.), and are over possible sequences where elements are from the Dictionary. In sequence to sequence architectures x is often the state s output by the encoder. Finding the maximum requires enumerating all sequences, which is exponential in sequence length.
We proposed earlier an inference method: , , …,
This is NOT optimal, it’s a greedy “best first” search.
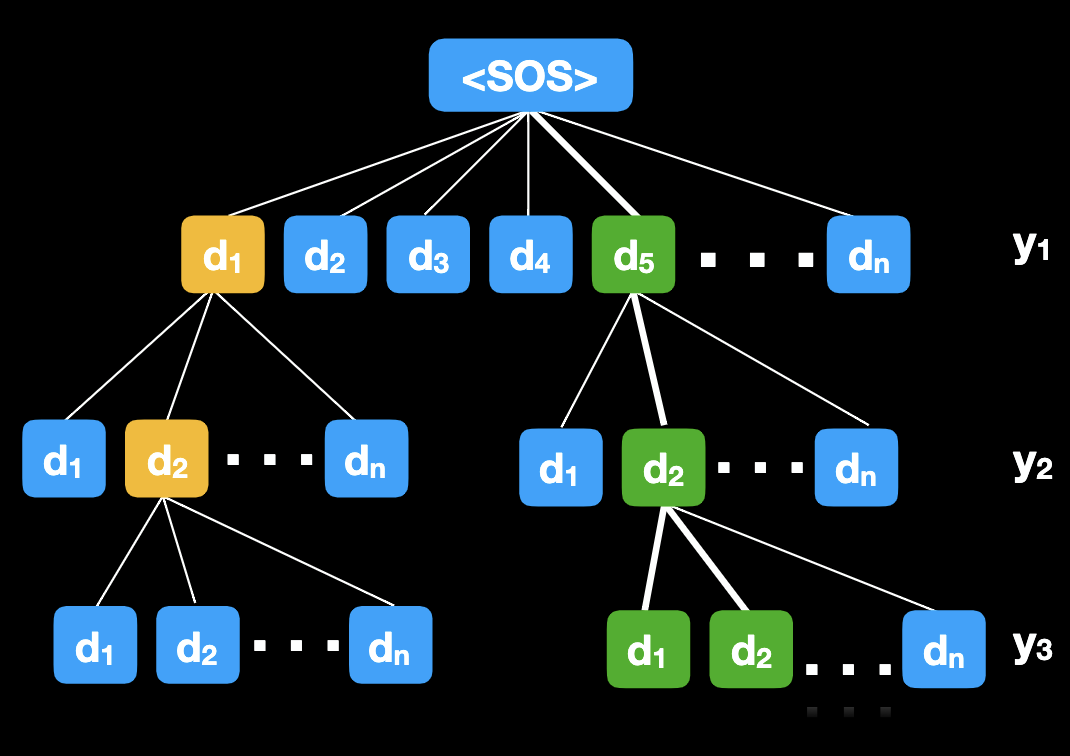
Inference can be viewed as searching a tree where the number of children of each node is the size of the Dictionary. Inference is a path through such tree. Exhaustive search is prohibitive due to the exponential complexity. Beam Search with beam size , goes layer by layer and explores $\beta $ paths through the tree with highest probability. Search ends when <EOS> is selected or max length is reached. This term is introduced for speech recognition by Raj Reddy in 1977.
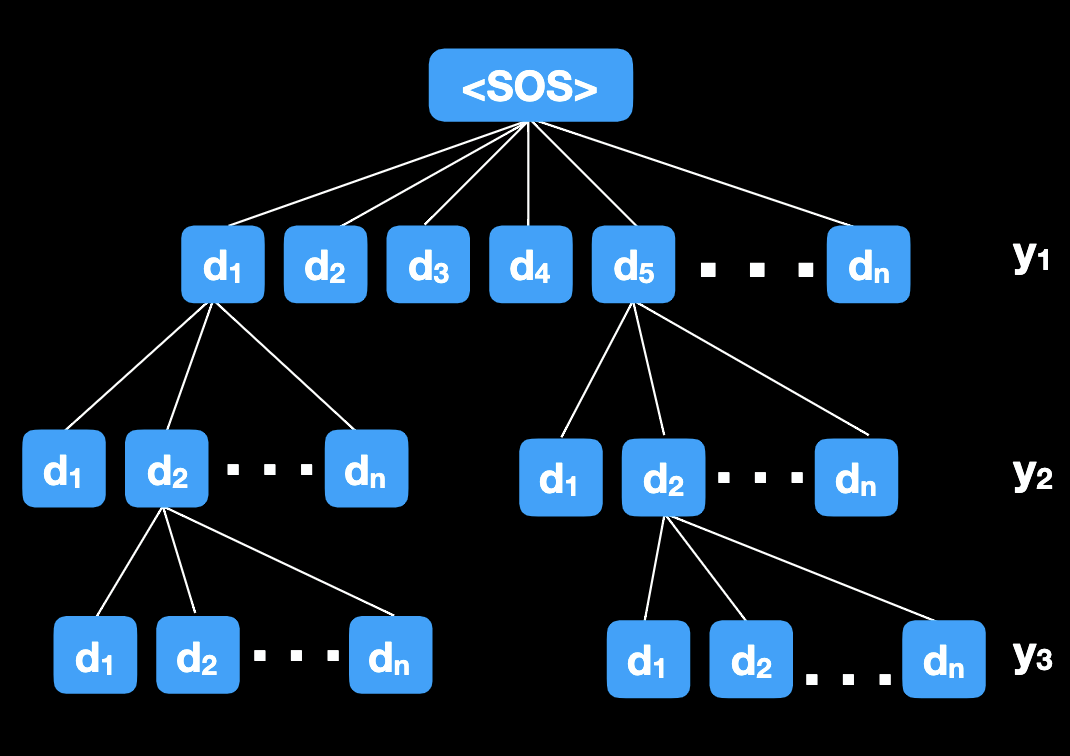
Let’s take Beam Search with as an example. We evaluate for all , retain two with largest . Then we evaluate for each selected above and for all , retain 2 paths with largest value. Similarly, we evaluate for each selected above and for all , retain 2 paths with largest value. We continue to deeper levels until <EOS> or max length etc.