Recurrent Neural Networks (RNN)
Vanilla Recurrent Neural Networks (RNN)
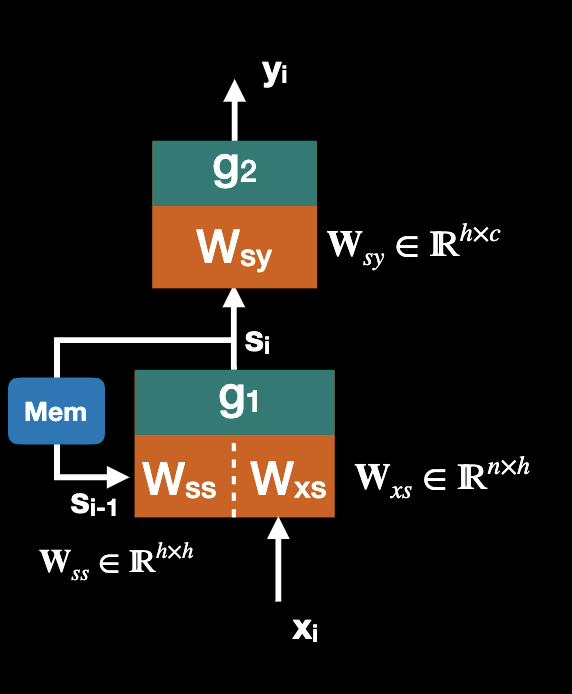
We start with a two layer feed forward network, where input x is a n-D vector representing the sequence elements, output y is C classes, and hidden layer s has h hidden nodes.
Then we have , where are activation functions. They are usually tanh and softmax functions respectively.

Now we add in a recurrent loop, this network is called Elman Network. But we noticed x, y, and s are indexed by sequence position i. We brushed under the rug that the state is delayed, and there must be memory to store previous state.
Then we have , note that state must be initialized, usually with a vector of zeros.
Training and inference
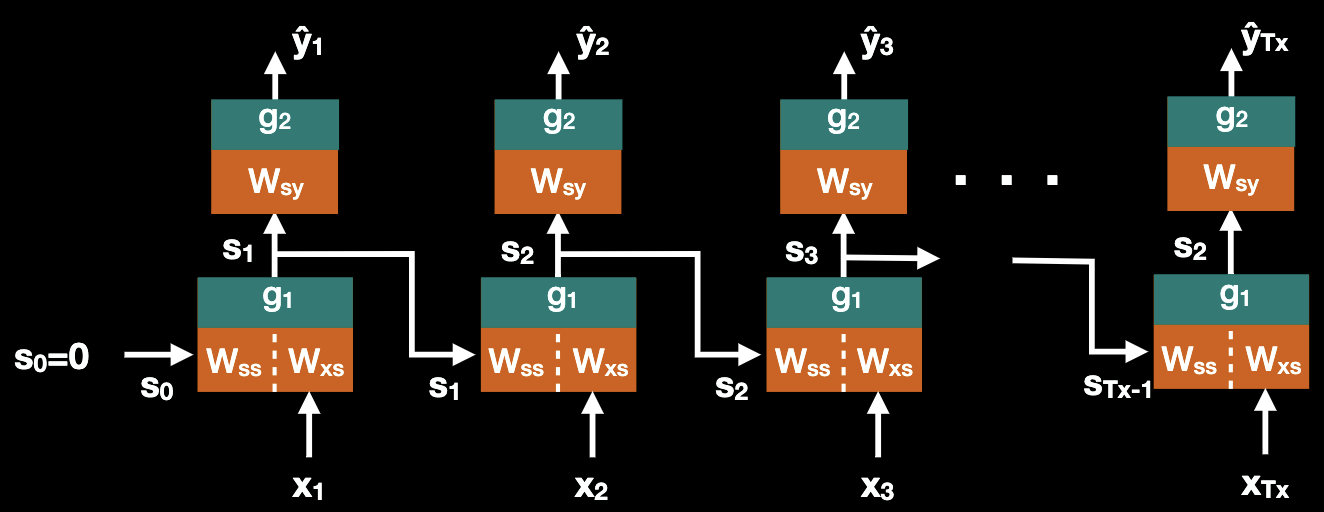
How do we train RNN? We use backdrop with a trick, we initialize state , with the first input we have ; similarly with the second input we have ; and with i th input we have . We unroll network over time for sequence of length T, remember all weights are shared.
Considering the task of sequence classification, the training pair is
- Input: sequence
- Training label: y is a class represented as a 1-hot vector
We use cross entropy as the loss function. This looks like a feedforward network. We train it using Stochastic Gradient Descent with Adam/RMSprop. The training procedure is called Back Propogation Through Time (BPTT), the unrolled network is deep with number of layers equals . And if loss function is defined over full output sequence, it’s still trainable by backdrop (BPTT).
This unrolling looks complicated to implement, yet it’s already implemented as part of training in the deep learning frameworks (Tensorflow, PyTorch, etc.)
Statistical Language models
A statistical language model is a probability distribution over sequence of words computed from some corpus. Consider a one word sequence, is just the probability of each word, which can be represented as a histogram. Now consider a two word sequence, is the probability of ordered word pairs.
-
Is ?
No, It’s not symmetric as
-
Is ?
No, the two words are not independent either
Keep going bigger, is the probability of a sequence of five words being used in the language. Examples are P(‘the’, ‘cat’, ‘in’, ‘the’, ‘hat’) is the probability of the “The cat in the hat” appearing in a corpus of English text. P(‘a’, ‘q’, ‘t’, ‘i’, ‘u’) is the probability of the letter sequence “aqtiu” appearing in a corpus of English text. To fully represented English language, we would need a histogram with a exponential number of cells, say for 5 word sequence.
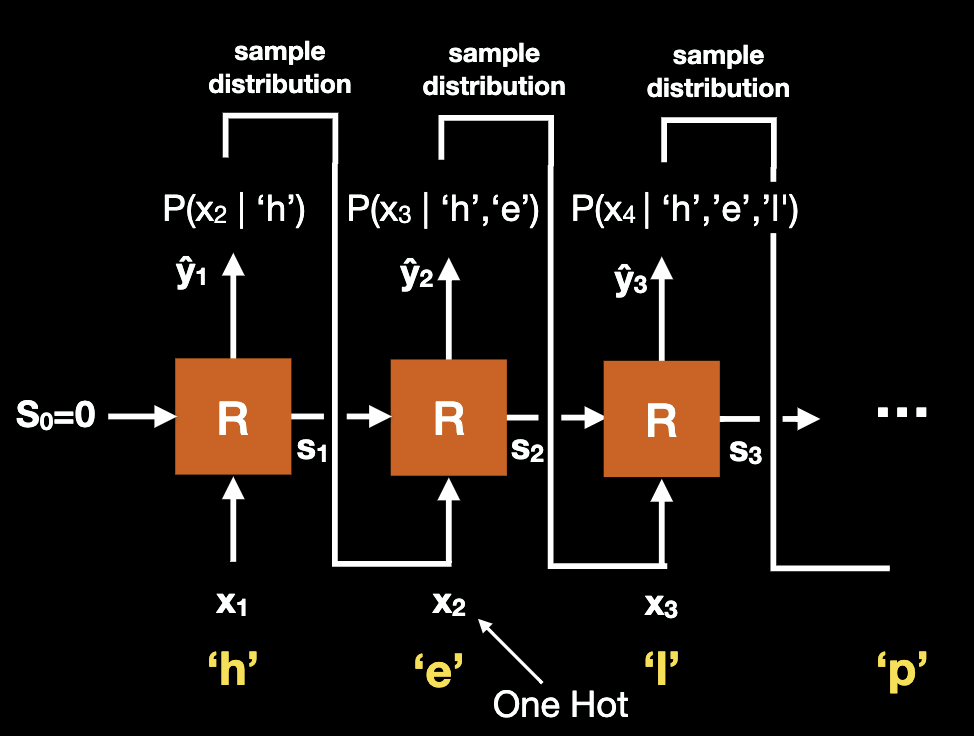
Let’s visit an example of using Character RNN implementing a language model. We assume x is an n-dimensional one-hot encoding of characters and includes punctuation, space (end of word). is also n-dimensional, but values are not limited to 0/1. In the RNN, final activation function is softmax, each output comprising can be viewed as the conditional probability of the next character. When a sequence has been input to a trained network, the output is the probability distribution

The network is trained using cross entropy loss to compare the next character from the training set to the output from the network. The training process takes sequences of characters, and put them in one at a time, comparing the predicted character to the next one.
How do we sample the output ? Recall is a vector of dimension equal to dictionary size, we will follow the steps:
- Take largest value (arg max)
- Randomly sample based on distribution.
- Blend using “temperature” of softmax function.
And how complicated is to code this up?

Teacher Forcing
The question raised from the chart above, what should be? We have several choices:
- Raw output of RNN
- A sampling of e.g. 1-Hot with one at arg max position.
- Teacher forcing: Use the actual rather than a sampling of . In this example, is ‘e’.

The advantages of Teacher Forcing is that it makes training more robust since errors don't accumulate, and the training converges faster. The disadvantage is that Inference is different than training which leads to exposure bias. Some alternatives to Teacher Forcing include Curriculum Learning and Professor Forcing.
Vanishing and exploding gradients
The problems with Vanilla RNN are mainly vanishing and exploding gradients:
-
Exploding gradients
Solution: Gradient clipping
-
Vanishing gradients
Solution: Regularization
-
Information doesn't propagate far back in time and easier elements of input sequence don't affect output.
Solution: Tastier network such as LSTM and GRU, these networks are also less prone to vanishing/exploding gradient problems.