Sequence processing tasks with deep learning
Sequences
Sequence is an ordered list of elements, it could be infinite or finite, with fixed or variable length. The examples of sequence are discrete samples of an electric signal; characters in poem, Bid/Ask prices etc. The characteristics of the sequences are:
- Samples of “continuous” value like temperature, stock prices, audio etc. Sampled uniformly in time (or not)
- Discrete values from a small set of possibilities (e.g. Roman characters, 1-10’s); Discrete values from a very large set of possibilities(e.g. words)
- High dimensional data (e.g. images)
Sequences are typically processed by digital signal processing model, finite state machines, learning automata, Markov models/Hidden Markov models, and our focus today: neural networks.
To give the notations for input/output sequences:
- Input sequence of length :
- Output sequence of length :
Input and output sequence elements may be in different types (e.g. text to speech). Input length could be 0,1, or arbitrary length , output length could be 1, or arbitrary length . Input length and output length could differ.
Examples of Sequence Modeling are list below:
| Task | Input | Output | |
|---|---|---|---|
| Music generation | None or context vector | audio | |
| Speech recognition | Audio | Text sequence | |
| Sentiment classification | Text sequence | Binary/Scores | |
| Language translation | Text sequence | Text sequence | |
| Video activity recognition | Image sequence | Category | |
| Named entity recognition | Text sequence | Entity sequence | |
| Prediction | Sequence of elements | Next element | |
| Image captioning | Image | Text sequence |
We found direct application of the three sequence models highlighted above in the finance realm.
- Sentiment classification. it’s just like extract sentiment from movie reviews.
- Named entity recognition. it takes a sequence of text as input, it gives it label for each word ( person, place, not a named entity) as output.
- Prediction. When elements of sequence are real numbers, methods like linear extrapolation are often used, when elements are categorical (e.g. text), learning is needed.
Sequences Processing
The sequence processing can be modeled in different forms:
- General sequence processing: function f where
- Causal sequence processing with window size k+1: function g that is applied repeatedly for
- Noncausal sequence processing with window size 2k+1: function g where
- Casual sequence processing being applied to both inputs and outputs: function g’ where
- Recursive causal sequence processing, it introduce a new sequence state: and two update equations , where
Put them graphically:
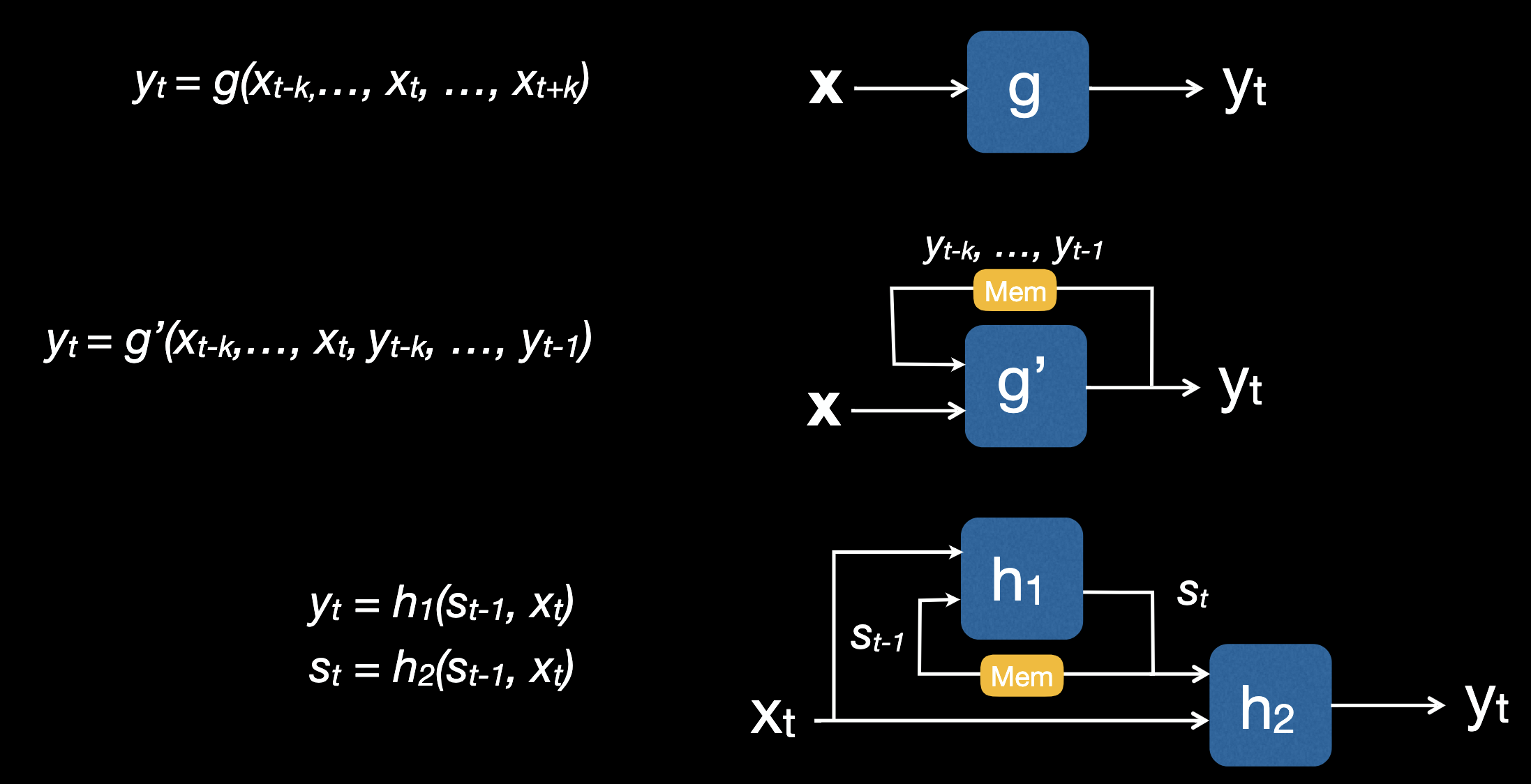
Causal sequence processing
can be re-written recursively where the state is simply k previous inputs and outputs
, and update is
.For example, Exponential Moving Average (EMA) could be recursively written as
,
.
So the takeaways here are:
- The state can include previous outputs.
- Output of recursive processing can be affected by inputs from long ago (infinite past), and this is both good and bad, good because it provides long term memory well beyond the window size, bad because outlier inputs may have an effect that persists.
FeedForward Networks
Inference is the task that given x then we evaluate f(x). Classification is the kind of inference that given an input x, which of C classes is it?
Bayesian classifier defines where is the conditional probability of the class given the feature . Bayesian classification is the best classifier ever…sort of. It’s the best because it has the lowest probability of error of any classier! And the “…sort of” lies in how should be represented? How many training samples are needed? How do we learn given a training set? How do we perform inference?
Nowadays we use multilayered network to train the model for inference. A single node of such network (or we say single layer network) looks like below:
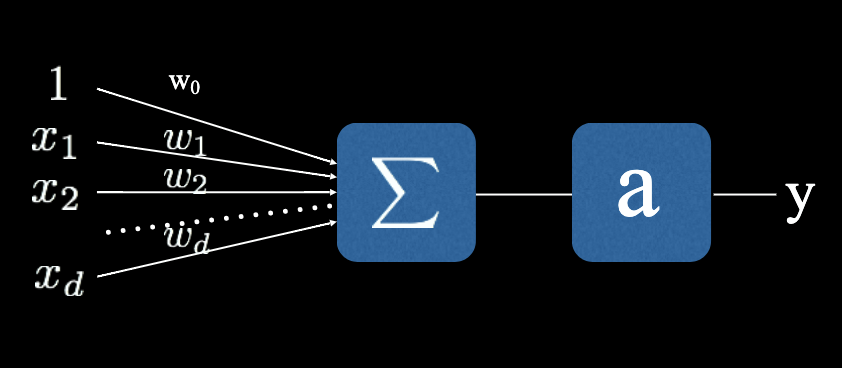
It’s modeled as:
Where x is the input vector padded with 1, w is the weights including bias, a is the activation function.
Activation function
We hereby list out the common types of activation functions:
- Sigmoid
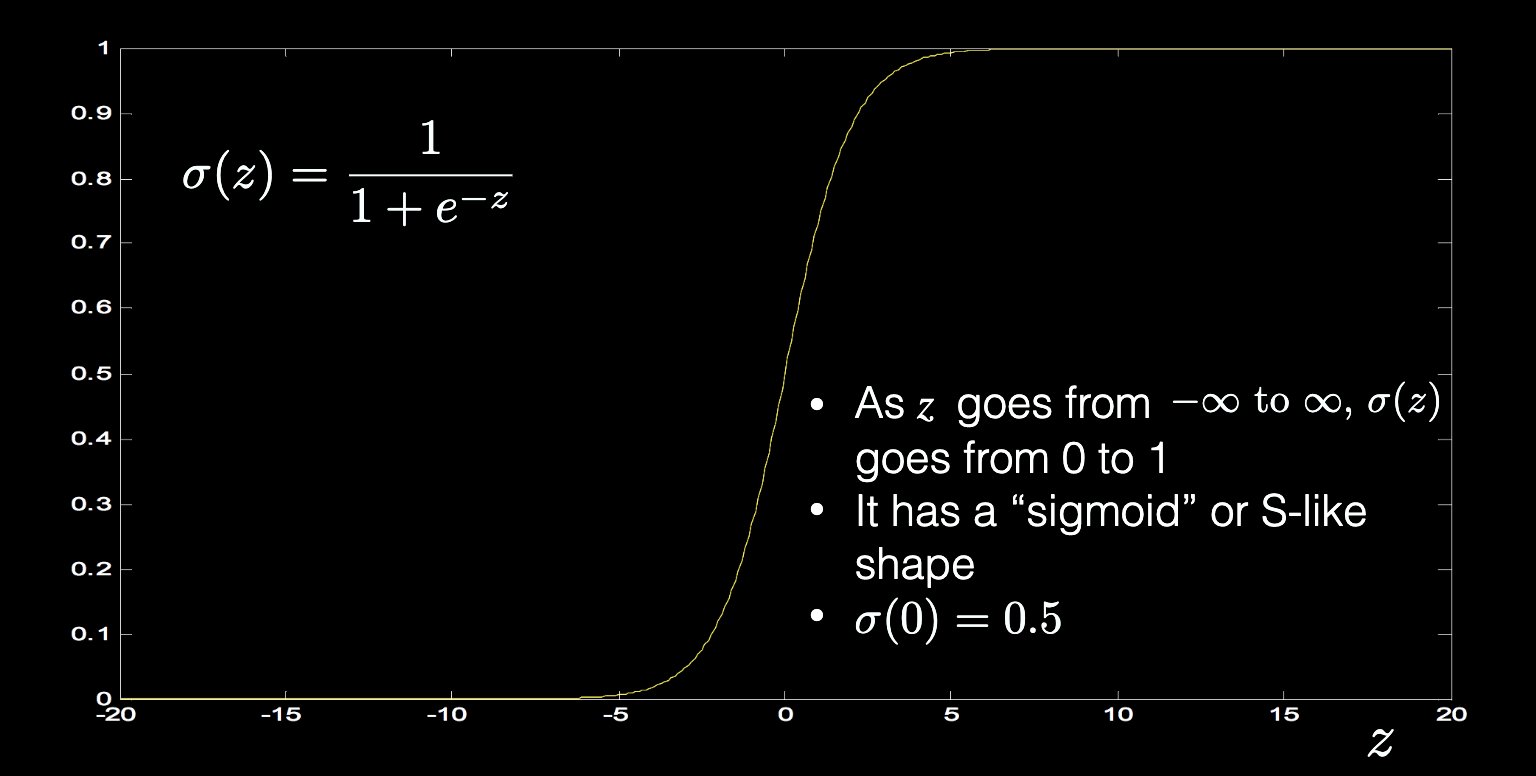
-
Tanh
As x goes from negative infinity to positive infinity, tank(x) goes from -1 to 1. It has a “sigmoid” or S-like shape, and tanh(0) = 0
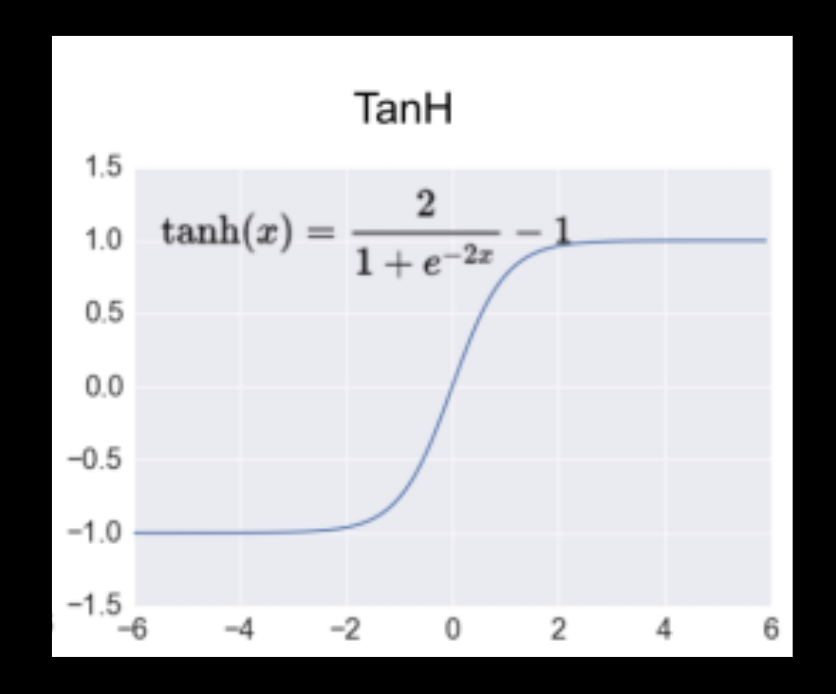
-
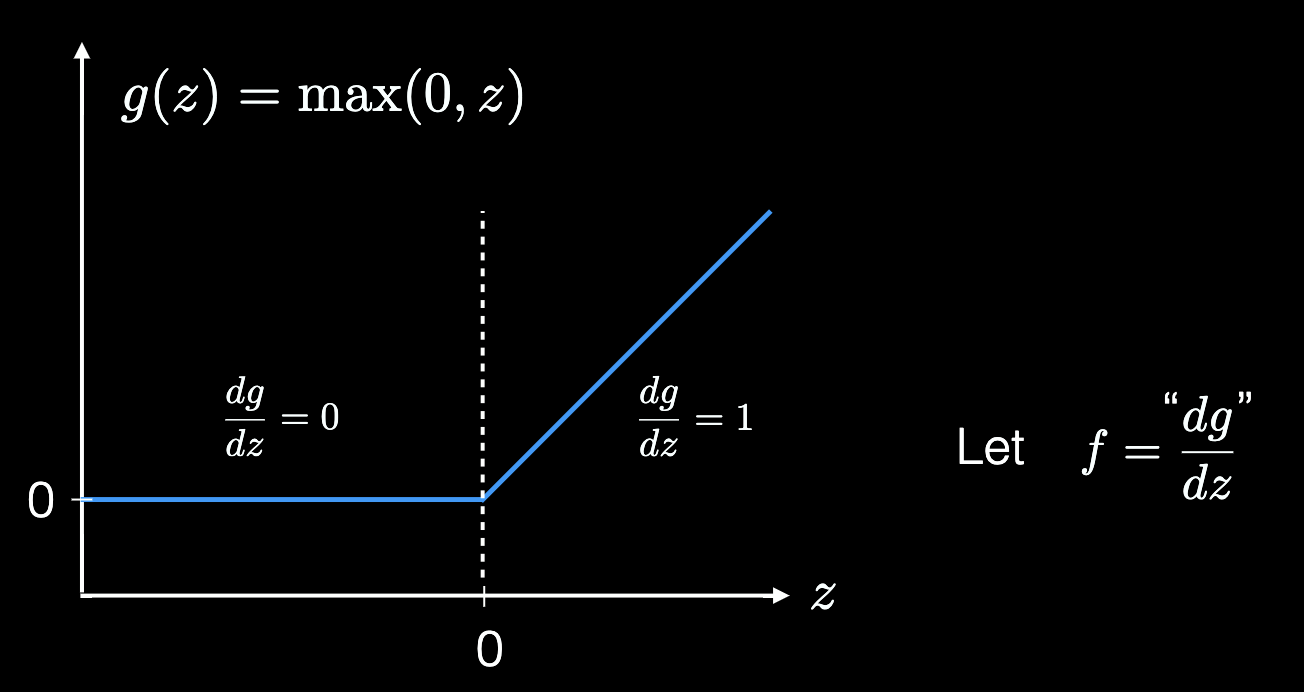
Rectified Linear Unit (ReLU)
In the similar manner, a two layer network looks like below
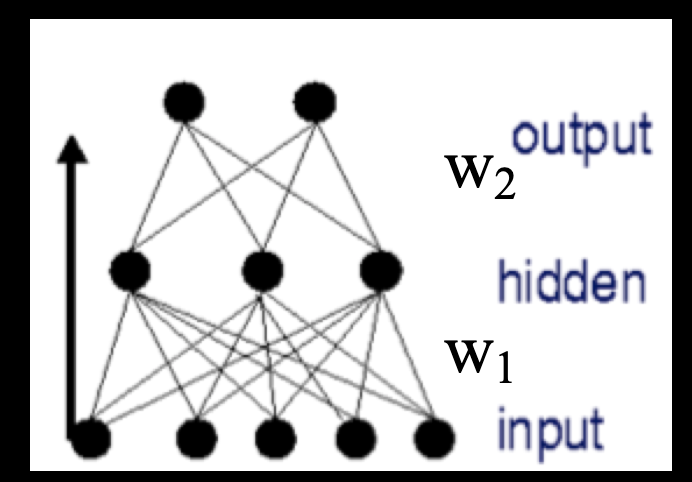
, here we have two sets of weights, and weights for each layer are represented as a matrix; we also have two activation functions.
Feedforward Networks are composed of functions represented as “layers” with weights associated with layer I and is the activation function for layer i. Meanwhile can be a scalar or a vector function.
In PyTorch it is pretty simply to specify a two layer network.

To classify the input x into one of the C classes, we have C outputs . Ideally, output is the posterior probability of class i given the input x. e.g. . The outputs are positive, less than 1, and sum to 1: . Classification decision is . If the network were certain about the class, one output would be 1 and rest would be zero. This can be implemented with a softmax layer where z is the output of the previous layer .

Universal Approximation Theorem
If we have enough hidden units (one or more hidden layers) we can approximate “any” function with a two layer network.
So even though “any” function can be approximated with a. Network with single hidden layer, the network may fail to train, overfit, fail to generalize, or require so many hidden units as to be infeasible. This is both encouraging and discouraging.
However, academia showed that deeper networks are more efficient in that a deep rectified net can represent functions that would require an exponential number of hidden units in a shallow one hidden layer network. Deep networks composed on many rectified hidden layers are good at approximating functions that can be composed from simpler functions. And lots of taks such as image classification may fit nicely into this space.
Training data is a set of sequences pairs . Total Loss is a function . Training is to find a w that minimize the total loss.
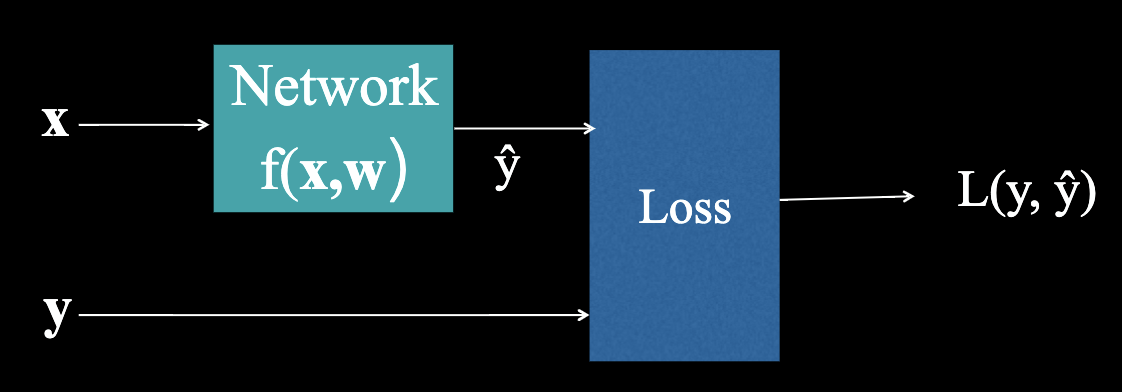
Loss function
Among the aforementioned, the loss function is really important. It's how we compare the network output to the training labels. We list out the common loss functions below
- Regression problems:
- Distance: , usually p=1 or 2
- Classification problems
- Cross Entropy: , where y is a vector with one 1 and rest 0s, is a vector with positive floats that sum to 1 (output of Softmax).
Cross entropy between the output of a network and ground truth y is commonly used when n classes are mutually exclusive. That is . since y is “one hot”, only one term of the sum is non-zero, and there is only a positive loss back propagating from that one output.
Cross entropy is the number of bits we’ll need if we encode symbols from y using the wrong distribution of . Minimizing cross entropy is minimizing the number of bits. It’s the same as minimizing the KL divergence between y and . Maximizing the likelihood of the output is the same as minimizing the cross entropy.
Given a training set , estimate (learn) w by making small. In this training procedure we need:
- Back propagation using Stochastic Gradient Descent
- Adagrad, RMSprop, ADAM
- Regularization: Dropout, Batch/Group/Instance Normalization
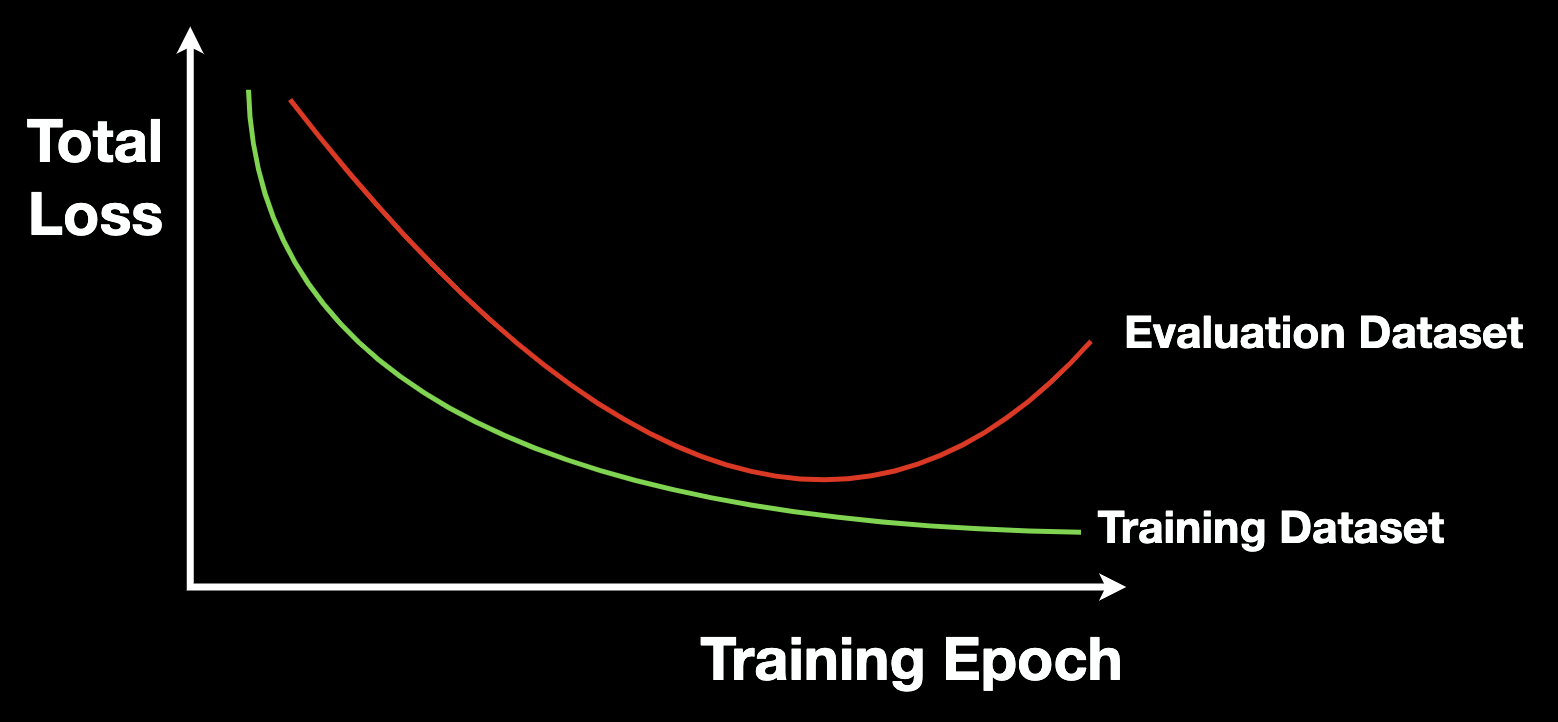
- Early Stopping
Feedforward Network for processing sequences
However there are problems with Feedforward Network for NLP:
-
Number of network weights become explosive in sequence length.
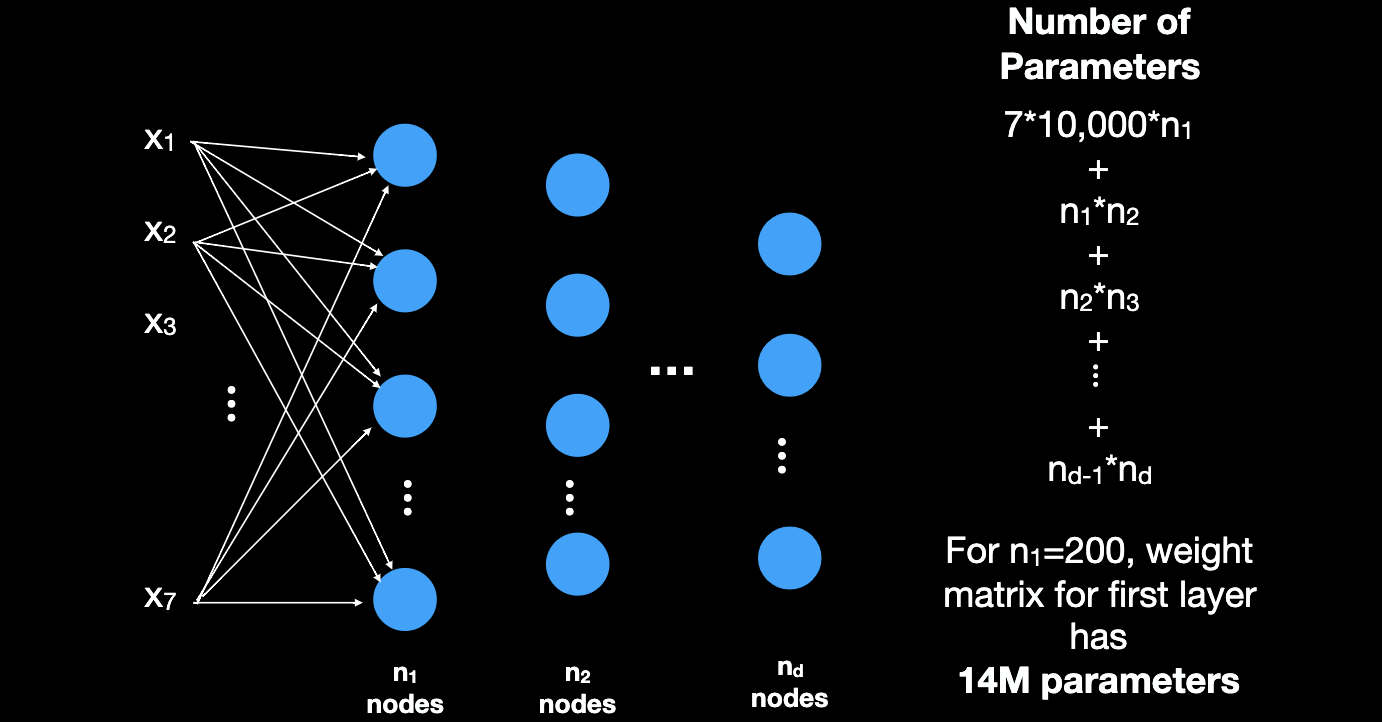
-
Input size is fixed.
-
Padding is possible, but then maximum sequence length means network is big. (First layer: Dictionary size * largest sequence length).
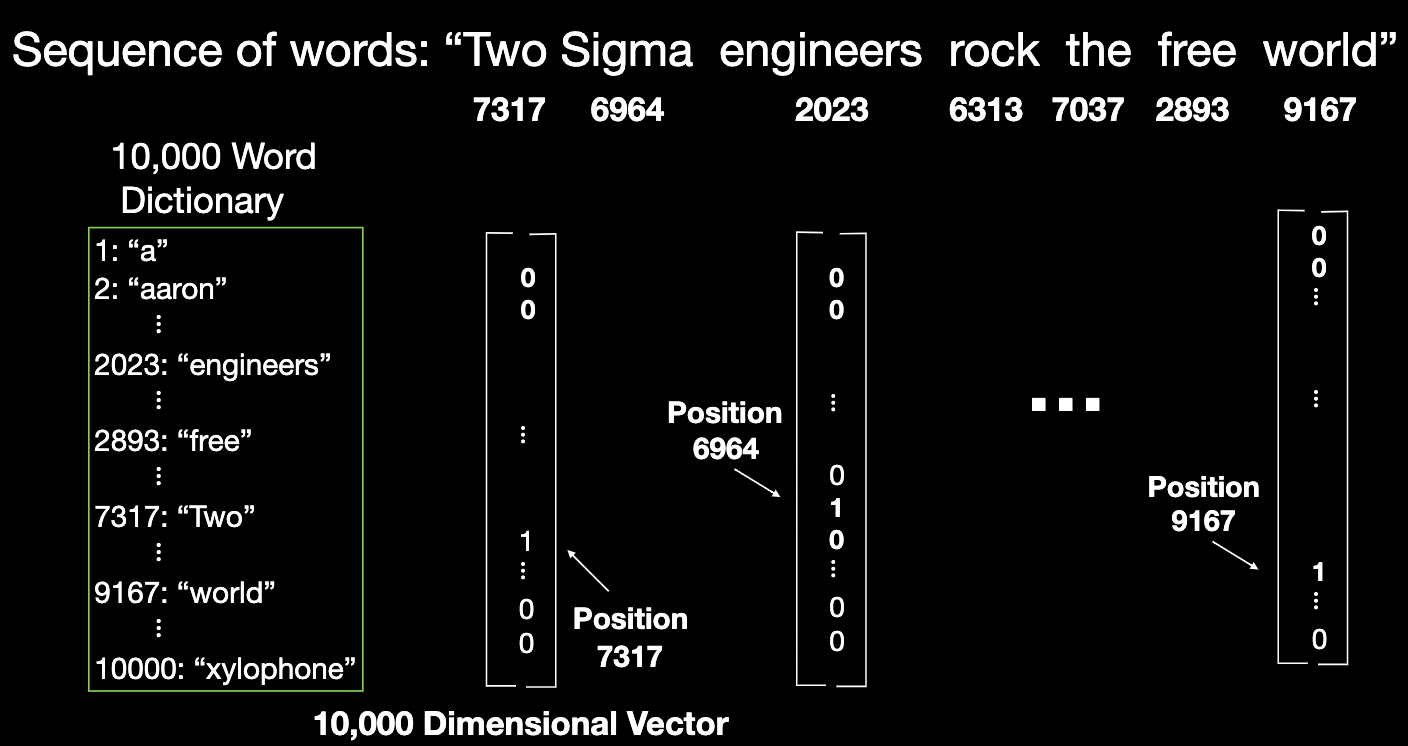
-
Output length is also fixed.
-
Doesn't share feature (weights) across sequence positions (harder to learn shift invariants).